
Hi, I'm Rubén Cañadas
My name is Rubén, and to be honest, I don't really know what I am.
I'm not a physicist.
I'm not a mathematician.
I'm not an AI engineer.
I'm not a software engineer.
Or maybe I'm a bit of all of them.
I like everything, I learn from everything, and I refuse to put myself in a box.
On a good day, we can talk about pseudo-Riemannian manifolds or tensor algebra.
On another, about how quantizing the Poisson bracket gives rise to commutators in quantum mechanics.
And if that feels too theoretical, we can jump straight into improving a multi-head attention mechanism or fine-tuning a Transformer with QLoRA.
Curiosity is the common thread.
That's why I've decided not to define myself on my own website.
I'm not a title. I'm not a label.
I'm just someone who's endlessly curious.
I could tell you about my career path, my degrees, my experience — all the usual stuff.
It would be perfectly fine.
But everyone does that.
That's what LinkedIn is for.
But anyway, here's what I've been focused on lately:
I'm bringing physics, mathematics, and artificial intelligence together in the world of computational biology.
The goal is not just to simulate molecules or predict structures.
It is to understand, in depth, how biology encodes information.
How physical laws, mathematical structure, and chemical constraints shape molecules and proteins.
How meaning emerges from form.
How function is written into matter.
Hidden inside molecular structures is an intrinsic language — a code shaped by evolution and physics.
By learning to read that code, we can build models that don't just predict outcomes, but understand.
Systems that capture structure, dynamics, and intent.
Systems that reason about biology, rather than approximate it.
That is the direction I'm exploring.
Things I'm Exploring Right Now
Topics and technologies I'm currently diving deep into
CUDA Kernels with Triton
Writing custom CUDA kernels using Triton to optimize inference, finetuning, and training pipelines. Achieving significant speedups in deep learning workloads.
Algebraic Topology for Molecular Docking
Exploring how topological data analysis and algebraic topology can help find optimal binding spaces for molecular docking simulations.
Preference Alignment (DPO, RLHF, RLAIF)
Studying and implementing preference alignment techniques like Direct Preference Optimization (DPO), RLHF, and RLAIF to better align language models with human preferences.
Personal Projects
Side projects I build to solve real problems in computational biology.

MolFun
Open-source framework for fine-tuning and adapting pre-trained protein structure prediction models like OpenFold. Features four fine-tuning strategies, modular architecture, and comprehensive experiment tracking.
4 Fine-Tuning Strategies
Head Only (~50K params), LoRA (~600K), Partial (~5M), Full (~93M)
Experiment Tracking
Native WandB, Comet, MLflow, Langfuse & HuggingFace integrations
Modular Architecture
Swappable components via registry: attention, blocks, structure modules
Complete Pipeline
Data loading, MSA handling, featurization, model export
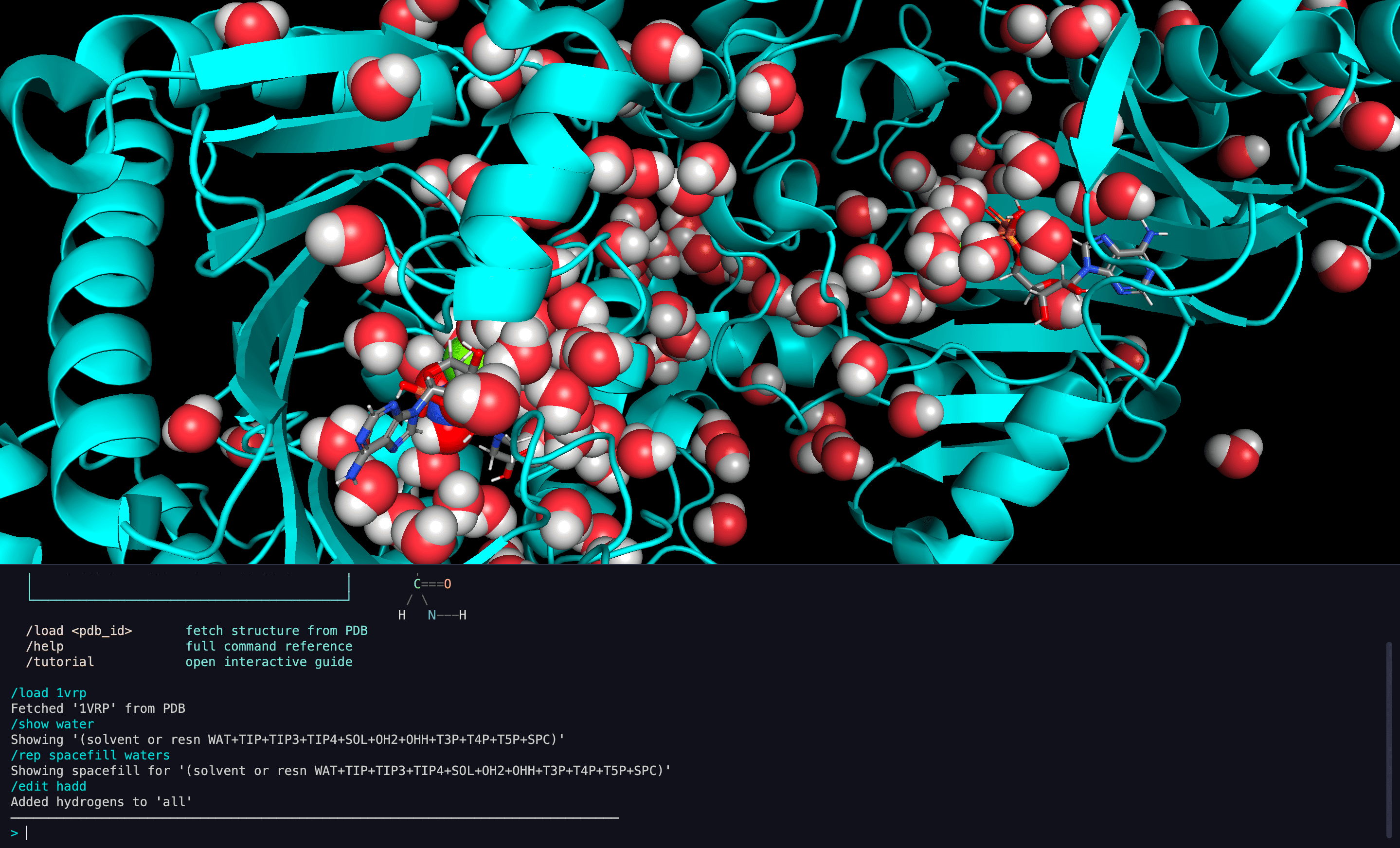
CodeMol
Desktop protein visualization app combining 3D molecular rendering with a terminal-style command console. Features 200+ Python tools, AI agent integration, and collaborative real-time sessions.
Console-First
Text commands instead of GUI menus for power-user workflows
200+ Tools
Across 27+ groups for visualization, analysis, and manipulation
AI Agent Integration
Natural language interaction via LLM agents with specialist routing
Trajectory Analysis
MD playback, RMSD tracking, clustering, multi-structure comparison

Agent Skills
Curated collection of production-tested skills for Claude Code that encode best practices for full-stack development, testing, security, and architecture.
Backend Development
FastAPI + DDD, SOLID principles, Pydantic validation, pytest testing
Web Development
Next.js/React with feature-first organization and ports & adapters
Cybersecurity
OWASP top 10, container hardening, prompt injection defense
Web Testing
Vitest + Testing Library, MSW mocking, accessibility testing
Ships & Builds
Turning ideas into profitable products that empower others to grow.

Nomosis - Molecular Intelligence Platform
Next generation molecular intelligence platform combining AI, molecular dynamics, and drug discovery tools. A complete ecosystem for molecular research, simulation, analysis, and discovery powered by AI agents.
- Pose & Trajectory Viewers
- Interactive research notebooks
- AI-powered HPC pipeline orchestration

Novachef - Recipe Revolution
Mobile app powered by artificial intelligence with 3000+ recipes. Features intelligent system for recipe questions, cooking tricks, shopping lists, menu creation, and AI chat agent expert in cooking.
- 3000+ recipes library
- AI-powered recipe assistant
- Shopping lists
Articles & Tutorials
Thoughts & Deep Dives
Exploring the frontiers of AI, machine learning, and computational biology. From practical tutorials to deep technical insights.
 Machine Learning
Machine LearningPositional Encoding in Transformers: From Sinusoidal to RoPE
Understand positional encoding in Transformers, from sinusoidal embeddings to RoPE, and learn how models capture token order and relative position.
 Machine Learning
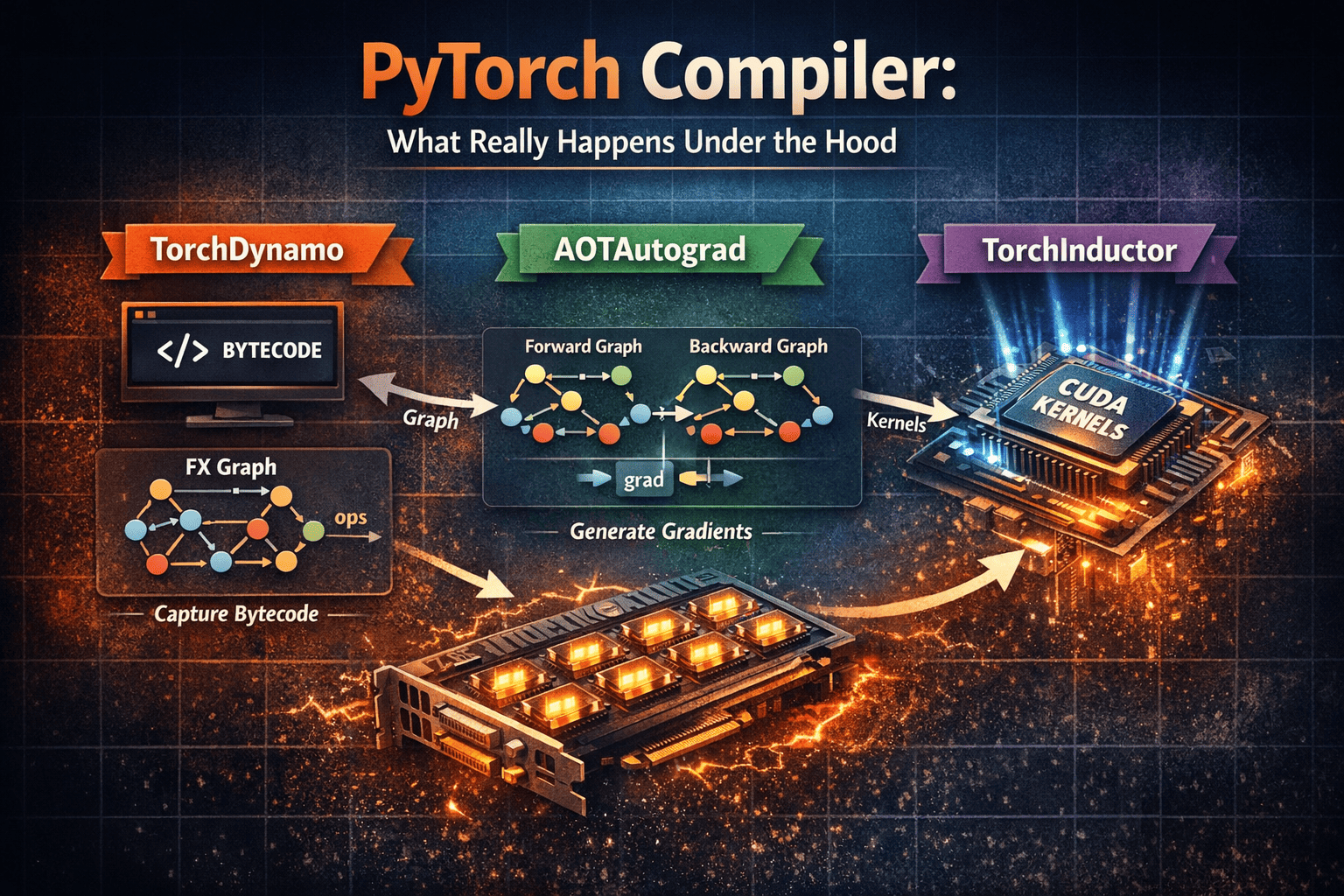
Machine LearningPyTorch Compiler Explained: TorchDynamo, AOTAutograd & TorchInductor
Understand how PyTorch compilation works under the hood: bytecode capture with TorchDynamo, forward/backward staging with AOTAutograd, and kernel optimization with TorchInductor.
 Machine Learning
Machine LearningUnderstanding Attention: The Idea Behind Modern AI
One paper changed everything: Attention Is All You Need. This post breaks down the foundations behind attention, starting from embeddings. A simple journey from words to meaning.
Get notified about new posts and projects
No spam, unsubscribe anytime. Your email is safe with me.
Contact
Let's Connect
Have a project in mind, a question about my work, or just want to say hello? I'd love to hear from you.
Get in Touch
Have a question or want to work together?